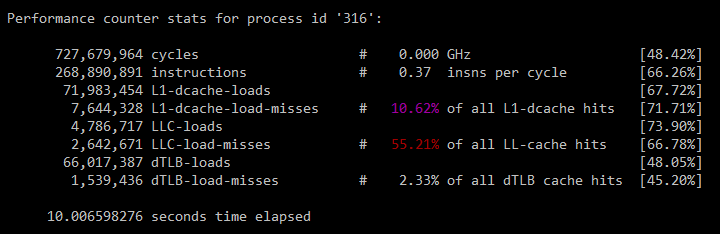
perf stat 输出解读
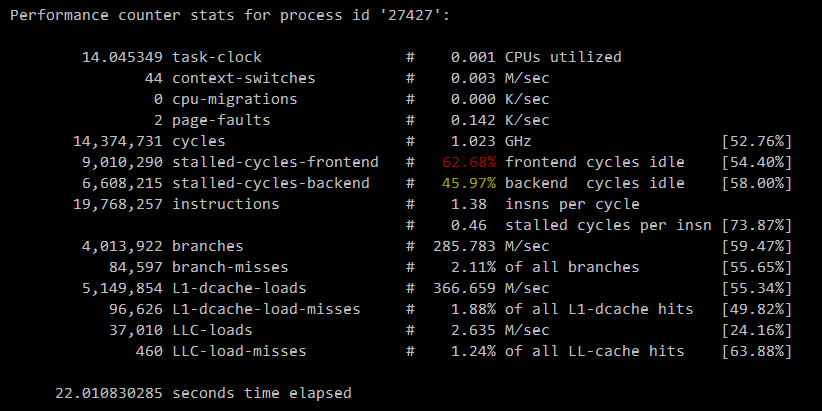
task-clock:用于执行程序的CPU时间,单位是ms(毫秒)。第二列中的CPU utillized则是指这个进程在运行perf的这段时间内的CPU利用率,该数值是由task-clock除以最后一行的time elapsed(也就是wall time,真实时间,单位为秒,下面的M/sec等数值都是除以这个数得到的)再除以1000得出的。context-switches:程序在运行过程中发生的上下文切换次数。这个指标值大家都很熟悉,就不细说了。cpu-migrations:程序在运行过程中发生的CPU迁移次数,即被调度器从一个CPU转移到另外一个CPU上运行。这里要注意下CPU迁移和上下文切换的不同之处:发生上下文切换时不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换。发生上下文切换时有可能只是把上下文从当前CPU中换出,下一次调度器还是将进程安排在这个CPU上执行。
page-faults:缺页。指当内存访问时先根据进程虚拟地址空间中的虚拟地址通过MMU查找该内存页在物理内存的映射,没有找到该映射,则发生缺页,然后通过CPU中断调用处理函数,从物理内存中读取。见下图所示的例子(MMU,Memory Management Unit,是CPU中负责将负责虚拟地址映射为物理地址的单元):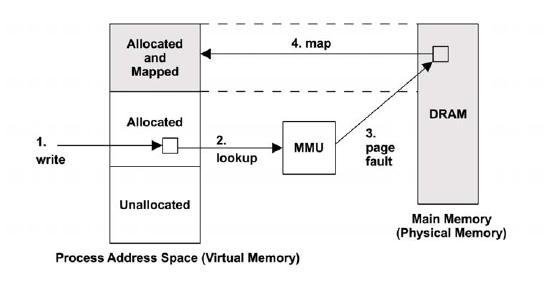
cycles:CPU时钟周期。CPU从它的指令集(instruction set)中选择指令执行。一个指令包含以下的步骤,每个步骤由CPU的一个叫做功能单元(functional unit)的组件来进行处理,每个步骤的执行都至少需要花费一个时钟周期。- 指令读取(
instruction fetch) - 指令解码(
instruction decode) - 执行(
execute) - 内存访问(
memory access) 寄存器回写(
register write-back)第二列中的
1.023G Hz这个值不是固定的,猜测(需要再查下资料)可能是在这段时间内的时钟频率(CPU时钟频率也可以由内核发起请求修改,或者由处理器自己动态调整。如内核空闲线程(kernel idle thread)可以请求CPU降低频率来节省能源)。stalled-cycles:字面意义是停滞周期,先介绍下instruction pipeline(姑且翻译为指令管道):指令管道是一种可以并行执行多个指令的CPU架构,通过同时执行不同的指令的不同组合实现。这类似于工厂的组装线,产品的不同阶段可以并行执行以提高吞吐量。考虑前面提到的指令步骤,如果每个步骤需要一个时钟周期,该指令则需要五个时钟周期来完成执行。在这个指令的每个单独的步骤中,只有一个功能单元是运行的,而其他四个是空闲的。通过使用指令管道,多个功能单元可以在同一时间运行,在管道中处理不同的指令。在理想状态下,处理器可以在一个时钟周期中完成一个指令。而stalled-cycles,则是指令管道未能按理想状态发挥并行作用,发生停滞的时钟周期。stalled-cycles-frontend指指令读取或解码的指令步骤,而stalled-cycles-backend则是指令执行步骤。第二列中的cycles idle其实意思跟stalled是一样的,由于指令执行停滞了,所以指令管道也就空闲了,千万不要误解为CPU的空闲率。这个数值是由stalled-cycles-frontend或stalled-cycles-backend除以上面的cycles得出的。instructions:该进程在这段时间内完成的CPU指令,之前在cycles已介绍过了。这是整个perf stat命令输出中最重要的指标值。第二列中的insns per cycle,简称IPC,表示一个时钟周期内能完成多少个CPU指令。该值越高,表示CPU的性能越好。第二行的stalled cycles per insn,表示完成每个指令,有多少个时钟周期是被停滞的,这个值越小,表示CPU的性能越好。该值是由stalled-cycles-frontend除以instructions得到的。为何不用
stalled-cycles-backend来除,或两个stalled-cycles加起来再除,个人估计是stalled-cycles-frontend停滞了,肯定stalled-cycles-backend也会停滞,因此可预见前者的值肯定会比后者要大(跑了几次验证确实如此),因此后者是受前者影响的,用前者来除比较靠谱。branches:这段时间内发生分支预测的次数。现代的CPU都有分支预测方面的优化。分支预测有什么好处请见stackoverflow上的这个帖子。branches-misses:这段时间内分支预测失败的次数,这个值越小越好。L1-dcache-loads:一级数据缓存读取次数。L1-dcache-load-missed:一级数据缓存读取失败次数。LLC-loads:last level cache读取次数。LLC-load-misses:last level cache读取失败次数。
要理解CPU缓存是什么,需要先了解下CPU的缓存架构,如下图:
 1.
1. level-1 data cache:一级数据缓存(I$)
2. level-1 inst cache:一级指令缓存(D$)
3. MMU:内存管理单元
4. TLB:转换后援缓存(translation lookaside buffer)
5. level-2 cache:二级缓存(E$)
6. level-3 cache:三级缓存
处理器读取数据过程如下面两个图:
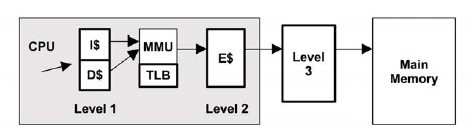
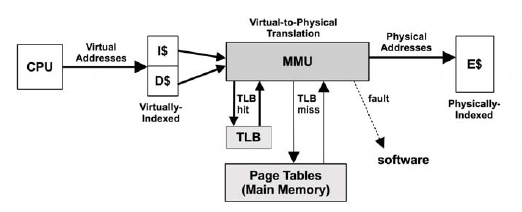
- CPU根据虚拟地址尝试从一级缓存(存放的是虚拟地址的索引)中读取数据;
- 如果一级缓存中查找不到,则需向MMU请求数据;
- MMU从TLB中查找虚拟地址的缓存(换言之,
TLB是负责改进虚拟地址到物理地址转换速度、存放虚拟地址的缓存);- 如果TLB中存在该虚拟地址的缓存,则MMU将该虚拟地址转化为物理地址,如果地址转换失败,则发生缺页(图中的
fault分支),由内核进行处理,见上文所述;如果地址转换成功,则从二级缓存(存放的是物理地址的索引)中读取;如果二级缓存中也没有,则需要从三级缓存甚至物理内存中请求;- 如果TLB中不存在该虚拟地址的缓存,则MMU从物理内存中的转换表(
translation tables,也称为页表page tables)中获取,同时存入TLB;(注意,这个操作是硬件实现的,可以由MMU通过硬件直接从物理内存中读取);- 跳到第4步。
由此可见,L1-dcache-load-missed和LLC-load-misses的数值当然是越低越好了。另外还有dTLB-load-misses(dTLB是数据转换后援缓存)和iTLB-load-misses(iTLB是指令转换后援缓存)等指标值,具体可以用perf list看下其他的CPU指标值:
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
ref-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
minor-faults [Software event]
major-faults [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
L1-icache-prefetches [Hardware cache event]
L1-icache-prefetch-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-stores [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-prefetches [Hardware cache event]
LLC-prefetch-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-prefetches [Hardware cache event]
dTLB-prefetch-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
iTLB-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
branch-load-misses [Hardware cache event]
用-e选项指定相应的指标值,如:
perf stat -e cycles,instructions,L1-dcache-loads,L1-dcache-load-misses,LLC-loads,LLC-load-misses,dTLB-loads,dTLB-load-misses -p 316 sleep 10