贴下我之前写的一个sed小总结
SED编辑模式
# p 打印匹配行
sed -n '2 p' input.file
# d 删除匹配行
sed '2 d' input.file
# r 读取文件至匹配位置
sed '2 r sample.file' input.file
# w 将匹配行写入到文件
sed '2 w output.file' input.file
# i 在匹配行之前插入
sed '2 i strings' input.file
# a 在匹配行之后添加
sed '2 a strings' input.file
# s 替换模式
sed '2 s/orig/repl/g' input.file
# ! 选定匹配行之外的行
sed -n '2 ! p' input.file
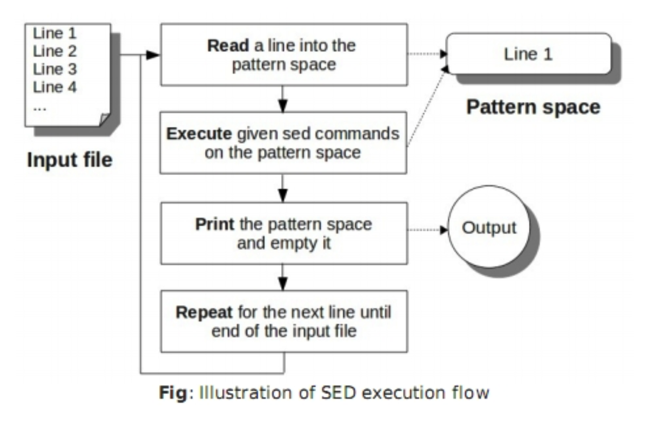
SED 处理流程图
三个常用的选项
-n不打印模式空间,通常与-p打印模式结合
sed '3 p' input.file # 将会把第三行打印两次,其中一次为模式空间
sed -n '3 p' input.file # 只会将第三行打印一次,不打印模式空间
-e增加执行命令,执行多次模式操作时使用
sed -e '1,3 d' -e 's/orig/repl/g' input.file
sed -e 's/orig1/repl1/g' -e 's/orig2/repl2/g' input.file
-i直接编辑输入文件而不只是在模式空间编辑
sed -i 's/orig/repl/g' input.file
指定地址范围
默认对整个输入进行处理,可通过指定地址空间只对指定范围进行处理。
# 只删除第 2 行
sed '2 d' input.file
# 在第 1 到 4 行每行之前插入一行 hello
sed '1,4 i hello' input.file
# 只打印第 4 行到最后一行,$表示最后一行
sed -n '4,$ p' input.file
修改地址范围
- 逗号(
,)
- 从第 m 行到第 n 行
'm,n',如sed '3,10 d' input.file- 从匹配行至第 m 行
'/RegEX/,m',如sed '/RegEX/,10 d' input.file- 从匹配行 1 至匹配行 2
'/EX1/,/EX2/',如sed '/EX1/,/EX2/ d' input.file
- 加号(
+)
- 从第 m 行起及之后的第 n 行
'm,+n',如sed '2,+4 d' input.file- 从匹配行起及之后的第 m 行
'/RegEX/,+m',如sed '/RegEX/,+4 d' input.file
- 波浪线(
~)
- 从第 m 行起每隔 n 行
'm~n',如sed '1~2 d' input.file
正则表达式
^一行的开始
# 匹配以 strings 开头的行
sed -n '/^strings/ p' input.file
# 在每行开头插入 strings
sed 's/^/strings/' input.file
$一行的结尾
# 匹配以 strings 结尾的行
sed -n '/strings$/ p' input.file
# 在每行结尾添加 strings
sed 's/$/strings/' input.file
.除换行符之外的任意一个字符
# 匹配符合 strings 后有任意一个字符的行
sed -n '/strings./ p' input.file
*之前的字符出现零次或以上
# 匹配 string、strings 或 stringss、stringsss
sed -n '/strings*/ p' input.file
注:
.*代表任意字符,但需注意 SED 没有非贪婪模式,如字符串'<a href="http:www.abc.com">www.abc.com<\a>'若使用<.*>将匹配整个字符串 而不是<a href="http:www.abc.com">或<\a>
\+之前的字符出现一次或以上(加号需转义)
# 匹配 strings、stringss、stringsss,不匹配 string
sed -n '/strings\+/ p' input.file
\?之前的字符出现零次或一次(问号需转义)
# 匹配 string 或 strings,不匹配 stringss
sed -n '/strings\?/ p' input.file
[0-9] [a-z] [A-Z]字符组
# 匹配含有数字的行
sed -n '/[0-9]/ p' input.file
# 匹配含有小写字母的行
sed -n '/[a-z]/ p' input.file
# 匹配含有大写字母的行
sed -n '/[A-Z]/ p' input.file
# 匹配含有字母或数字的行
sed -n '/[0-9a-zA-Z]/ p' input.file
[^]匹配不在指定字符组内的任一字符
# 匹配不含数字的行
sed -n '/[^0-9]/ p' input.file
# 删除每行中的 <...> 这类 html tag
sed 's/<[^>]*>//g' input.file
\<词首定位符\>词尾定位符
# 匹配含有 cat 的单词,不匹配单词 cats 或 scat 或 scats
sed -n '/\<cat\>/ p' input.file
\{m\}之前的字符连续出现 m 次({}需转义)
# 匹配 root,但不匹配 rot 或 rooot
sed -n '/ro\{2\}t/ p' input.file
\{m,\}之前的字符连续出现至少 m 次,最多次数无上限
# 匹配 root 或 rooot,但不匹配 rot 和 rt
sed -n '/ro\{2,\}t/ p' input.file
\{,m\}之前的字符连续出现最多 m 次,最小次数为 0
# 匹配 rt、rot、root,但不匹配 rooot
sed -n '/ro\{,2\}t/ p' input.file
\{m,n\}之前的字符连续出现至少 m 次,最多 n 次
# 只匹配 rot 或 root
sed -n '/ro\{1,2\}t/ p' input.file
\|或操作(|需转义)
# 匹配 david 或 DAVID
sed -n '/david\|DAVID/ p' input.file
替换模式
sed '[address-range|pattern-range] s/original- string/replacement-string/[substitute- flags]' input.file
- address-range|pattern-range
可选项,在四、五两节已说明
- s
指明替换模式
- /.../.../
分隔符,可另指定,如
's#orgi#repl#'或's%orgi%repl%'
- original- string
要替换的字符
- replacement-string
替换后的字符
- substitute-flags
可选项,替换标志,如没有则为替代每行中的第一个匹配字符
nn 表示数字,只替代该行中的第 n 个匹配字符g全局替代,替代每行中所有的匹配字符p打印w写入文件i忽略大小写e执行标志,将模式空间替代后的行当成 shell 命令执行 (这个比较猛)
# 只替代每行中的第 2 个 orig
sed 's/orig/repl/2' input.file
# 替代每行中所有的匹配字符
sed 's/orig/repl/g' input.file
# 打印替代后的行
sed 's/orig/repl/p' input.file
# 替代后的模式空间输出为 output.file
sed 's/orig/repl/w output.file' input.file
# 忽略要匹配的 orig 的大小写
sed 's/orig/repl/i' input.file
# 检查 runlevel 5 下各服务的状态
ls /etc/rc5.d/S* | sed 's/$/ status/e'
# 多种替换标志的结合
sed 's/orig/repl/gpiw output.file' input.file
- 替换模式中的其他语法
\(..\)保存匹配的字符
\n调用已保存的匹配字符,n 代表数字 1~9 (最多可保存 9 个)
echo 'A Blue Cat' | sed 's/\([ABC]\)/[\1]/g'
echo -e '020-12345678' | sed 's/\([0-9]\{3\}\)-\([0-9]\{8\}\)/[\1]-[\2]/g'