Impala表使用Parquet文件格式
参考官方文档。
准备了一个 427144792 行的 textfile 格式表 t_item:
[impale-host:21000] > select count(1) from t_item;
Query: select count(1) from t_item
+-----------+
| count(1) |
+-----------+
| 427144792 |
+-----------+
Fetched 1 row(s) in 191.67s
该表在 hdfs 存储的大小:
$ sudo -u hdfs hadoop fs -du -s -h /user/hive/warehouse/t_item
44.5 G 133.6 G /user/hive/warehouse/t_item
现在我们使用默认的 snappy 压缩方式创建一个 parquet_snappy_t_item 表:
[impale-host:21000] > create table parquet_snappy_t_item like t_item stored as parquet;
Query: create table parquet_snappy_t_item like t_item stored as parquet
Fetched 0 row(s) in 0.36s
[impala-host:21000] > set COMPRESSION_CODEC=snappy;
COMPRESSION_CODEC set to snappy
[impala-host:21000] > insert into parquet_snappy_t_item select * from t_item;
Query: insert into parquet_snappy_t_item select * from t_item
Inserted 427144792 row(s) in 421.85s
先看下数据的压缩情况:
$ sudo -u hdfs hadoop fs -du -s -h /user/hive/warehouse/parquet_snappy_t_item
7.3 G 14.5 G /user/hive/warehouse/parquet_snappy_t_item
已经压缩到了原先的 1/6 左右,符合我们对 snappy 压缩算法的预期。
那么对数据查询有没有什么影响:
先跑下 count 看看:
[impala-host:21000] > select count(1) from parquet_snappy_t_item;
Query: select count(1) from parquet_snappy_t_item
+-----------+
| count(1) |
+-----------+
| 427144792 |
+-----------+
Fetched 1 row(s) in 2.60s
2.60s vs 191.67s 好惊人的优化。
不过经同事提醒,可能是 Parquet 将行数预先存储在元数据里面了。
那再跑一下 group by :
[impala-host:21000] > select count(item_id), item_id from parquet_snappy_t_item group by 2 order by 1 desc limit 10;
... 省略输出 ...
Fetched 10 row(s) in 11.62s
而相对于原先 textfile 格式的表:
[impala-host:21000] > select count(item_id), item_id from t_item group by 2 order by 1 desc limit 10;
... 省略输出 ...
Fetched 10 row(s) in 189.42s
11.62s vs 189.42s 优势依然明显。
再来比较下 gz 和 snappy 压缩:
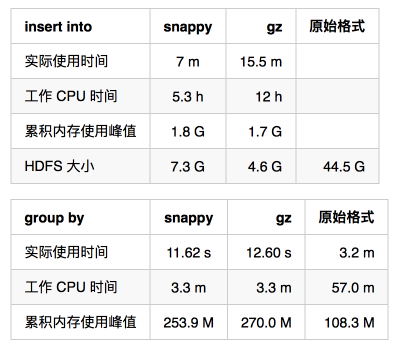
gz 的优势在于进一步将数据压缩到了 1/10,但是用时也多了一倍,但是在查询中的 CPU 和内存比较 snappy,相差并不大。
以上。
既压缩了数据还能优化了查询速度,这么逆天的黑科技,还不赶紧用起来?