使用Keras卷积神经网络
这篇文章记录如何用 Keras 实现 卷积神经网络 CNN,并训练模型用于图片分类;以及 CNN 中一些超参的调整和自己的理解。
数据集
http://www.ivl.disco.unimib.it/activities/large-age-gap-face-verification/

这个图片数据集是一些名人的少年时和成年后的对比照片,格式为 100*100,RGB。
将图片分成成年和少年两个类别,实现的分类器是个二分器,训练出来的模型能够对输入的照片进行分类,给出一个 old 或者 young 的 label。
整理数据集为如下目录结构:
train
├── old
│ ├── 1200 张图片
├── young
│ ├── 1200 张图片
validation
├── old
│ ├── 600 张图片
├── young
│ ├── 600 张图片
test
├── old
│ ├── 110 张图片
├── young
│ ├── 110 张图片
train 为训练组,validation 为验证组,训练时使用交叉验证,train 和 validation 的数据都会使用。
test 为验证模型的测试组。
图片展示
以下是 train/old 组展示的部分图片:
%matplotlib inline
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
some_old_pics = os.listdir('train/old')
show_rows = show_columns = 5
for k in range(show_rows * show_rows):
image = mpimg.imread('train/old/%s' % some_old_pics[k])
plt.subplot(show_rows, show_rows, k+1)
plt.imshow(image)
plt.axis('off')

“平均脸”
其实就是求每组图片的平均值,代码参考这里。
import os, numpy, PIL
from PIL import Image
import matplotlib.pyplot as plt
def plot_average_pic(group):
dirs = ["%s/%s" % (group, i) for i in ['old', 'young']]
for k in range(len(dirs)):
dir = dirs[k]
imlist = ['%s/%s' % (dir, c) for c in os.listdir(dir)]
w, h = Image.open(imlist[0]).size
N = len(imlist)
arr = numpy.zeros((h, w, 3), numpy.float)
for im in imlist:
imarr = numpy.array(Image.open(im), dtype=numpy.float)
arr = arr + imarr / N
arr = numpy.array(numpy.round(arr), dtype=numpy.uint8)
image = Image.fromarray(arr, mode="RGB")
plt.subplot(2, 3, k+1)
plt.imshow(image)
plt.title(dir)
plt.axis('off')
结果如下:

好神奇 ...
从“平均脸”这个结果来看,两组 label 确实有比较明显的区分。
创建 CNN 模型
导入的模块:
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
先定义好一些参数,所有图片的输入尺寸 (100*100,RGB 三通道),train / validation 样本数,训练轮次 epochs,以及小批量梯度下降训练样本值 batch_size:
img_width, img_height = 100, 100
train_data_dir = './train'
validation_data_dir = './validation'
nb_train_samples = 1200
nb_validation_samples = 600
epochs = 100
batch_size = 16
input_shape = (img_width, img_height, 3)
创建 CNN
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
定义 train 和 validation 的 ImageDataGenerator,图像增强,用缩放、镜像、旋转等方式增加图片,以便扩大数据量:
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(
rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
开始训练:
from keras.callbacks import ModelCheckpoint, Callback, TensorBoard
filepath="1.weights-improvement-{epoch:02d}-{val_acc:.2f}.h5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
tensorboard = TensorBoard(log_dir='logs', histogram_freq=0)
callbacks_list = [checkpoint, tensorboard]
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=callbacks_list)

可以看到前几次训练之后验证组的准确率 ( val_acc ) 就可以达到 82% 左右了。
( 一个 epoch 用 i7 CPU 需要 180s,而 GTX1080 GPU 只需要 3s )
100 轮训练后成绩最好的结果:
loss: 0.2957 - acc: 0.8875 - val_loss: 0.2994 - val_acc: 0.9139
val_acc 比 acc 还要高 ...
Tenserboard 上看到的训练过程:
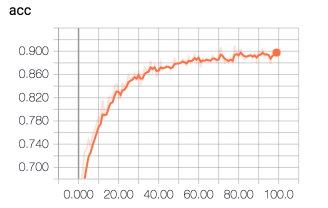
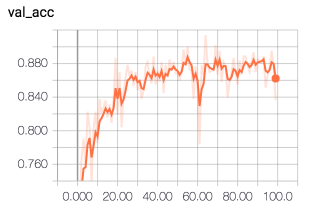
验证模型:
导入效果最好的模型
from keras.models import load_model
best_model = load_model('a.weights-improvement-64-0.91.h5')
还是用 ImageDataGenerator:
datagen = ImageDataGenerator()
test_generator = datagen.flow_from_directory(
'./test',
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
验证:
scores = best_model.evaluate_generator(
test_generator,
val_samples=220)
print scores
结果:
[2.7107817684386277, 0.82976878729858838]
准确率达到了 82.98%,效果还不错,但是距离训练时的 91.39% 还有一定的差距,比较明显的过拟合。
dropout
将模型中倒数第三层的 Dropout 参数,降低为 0.2,增加模型的泛化能力:
model.add(Dropout(0.2))
训练及测试结果:
[train] loss: 0.2599 - acc: 0.9008 - val_loss: 0.2315 - val_acc: 0.9105
[test] loss: 2.1801 - acc: 0.8636
准确率提升至 86.36% 。
optimizer
将 optimizer 从 rmsprop 更改为当前比较流行的 adam:
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
结果:
[train] loss: 0.1916 - acc: 0.9250 - val_loss: 0.3205 - val_acc: 0.9037
[test] loss: 1.4704 - acc: 0.8962
准确率进一步提升为 89.62% 。
从这次模型来看,测试结果与训练结果相当接近。
kernel size
将卷积层的卷积核大小从 (3,3) 改为 (5,5)
Conv2D(32, (5, 5), padding='same', input_shape=input_shape)
可以理解为增加了神经网络的权重参数数量,因为卷积层的权重参数数量,以第一层卷积层为例:
3 * (3 * 3) * 32 + 32 = 896
增大为:
3 * (5 * 5) * 32 + 32 = 2432
( 乘式前面的 3 为卷积层的深度,第一层是输入层的深度;后面的 32 为过滤器的个数,加上的 32 为 bias 个数,每个过滤器 1 个 bias )
结果:
[train] loss: 0.1104 - acc: 0.9533 - val_loss: 0.3632 - val_acc: 0.9003
[test] loss: 1.7149 - acc: 0.8902
可以看到训练时的训练组准确率达到了 95.33% 的较高水平,反映了权重参数数量增多的正面影响。
然而测试结果来看,与未改变卷积核大小时反而有些微下降,或许还应该降低 Dropout 的比例。
在此基础上将 Dropout 比例由 0.2 再次下降为 0.1,结果如下:
[train] loss: 0.1321 - acc: 0.9500 - val_loss: 0.3917 - val_acc: 0.8970
[test] loss: 1.4034 - acc: 0.9124
测试的准确率超过了 91% !
padding
将卷积层中的 padding 参数改为默认的 valid,即:
Conv2D(32, (5, 5))
保持 0.2 的 Dropout 比例
结果:
[train] loss: 0.1768 - acc: 0.9208 - val_loss: 0.3337 - val_acc: 0.8986
[test] loss: 1.7612 - acc: 0.8902
从结果来看并没多大的区别。
activation
测试更换激活函数。比如使用 PReLU,Keras 里使用 PReLU 需要使用 advanced_activations 类,模型修改如下:
from keras.layers.advanced_activations import PReLU
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=input_shape, activation='linear'))
model.add(PReLU())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (5, 5), activation='linear'))
model.add(PReLU())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (5, 5), activation='linear'))
model.add(PReLU())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
需要先声明一个 linear 激活函数的卷积层,然后再在后面增加一个 PReLU 层。
因为 PReLU 实际上会增加权重参数数量,因此使用了 0.1 的 Droupout。
结果:
[train] loss: 0.2656 - acc: 0.8850 - val_loss: 0.2623 - val_acc: 0.9054
[test] loss: 1.9551 - acc: 0.8737
试下 LeakyReLU(alpha=0.001)
[train] loss: 0.2002 - acc: 0.9267 - val_loss: 0.2987 - val_acc: 0.8885
然而在加载最佳结果 load_model 时有报错,没有执行最佳模型的测试。在最后一组训练得出的 val_acc: 0.8497 结果的模型上测试结果如下:
[test] loss: 2.1069 - acc: 0.8688
batch size
训练时的 batch size 对训练模型也有一定的影响,具体可参考知乎上的讨论。
实际测试如下:( 在之前 91% 测试准确率模型基础上修改 batch_size )
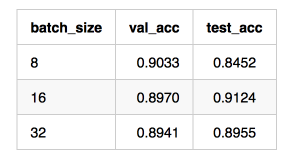
单从这个测试结果上看,还是 batch size 为 16 的最佳。
对比 batch size = 16 的训练过程,batch size = 8 的 acc 开始时上升较快,val_acc 震荡更为明显:
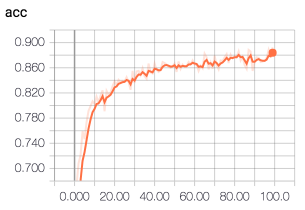

deeper
更深的网络。
再增加一层卷积层,模型修改如下:
model = Sequential()
model.add(Conv2D(32, (5, 5), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
结果:
[train] loss: 0.2415 - acc: 0.9075 - val_loss: 0.3782 - val_acc: 0.8581
[test] loss: 2.5879 - acc: 0.8361
可以看到过拟合严重了,或许对于数据量较少的训练集,使用更深的网络并不是一个较好的选择,比较容易出现过拟合。
最后
使用了测试结果为 91% 的模型,随便在谷歌上找了些图片进行测试,效果还不赖,如下图:
老年组 90% 准确率

温老四你怎么了 ...
少年组 95% 准确率

詹老汉亮了。
参考
https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html