MySQL 5.7 CPU 抖动问题的不完全处理过程
问题
我们内网有台机器,MySQL 版本为:
Server version: 5.7.17-11 Percona Server (GPL), Release 11, Revision f60191c
读写压力并不大,大概是每十分钟有个定时任务写入一定数量的数据:
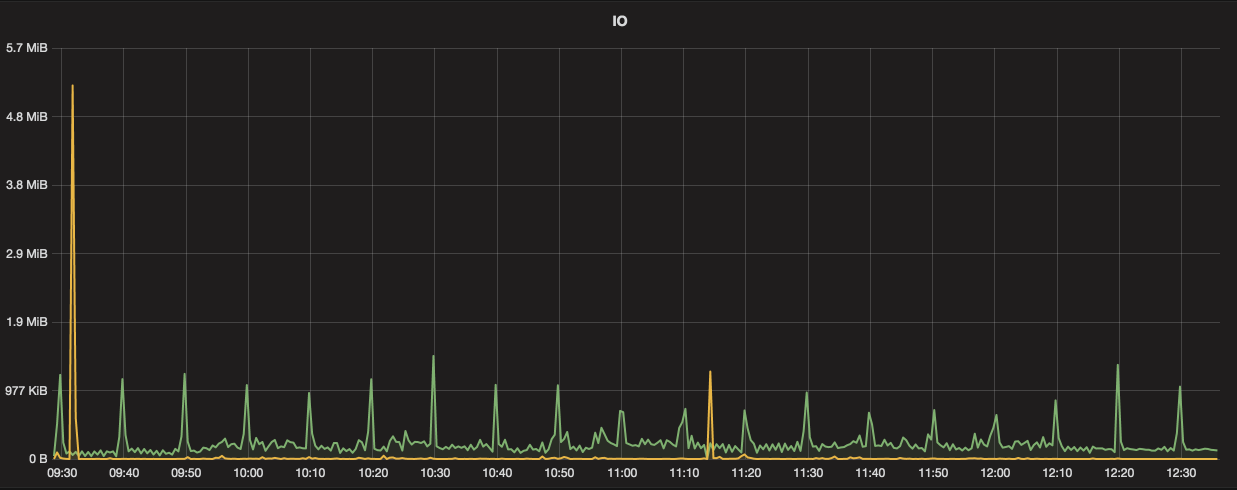
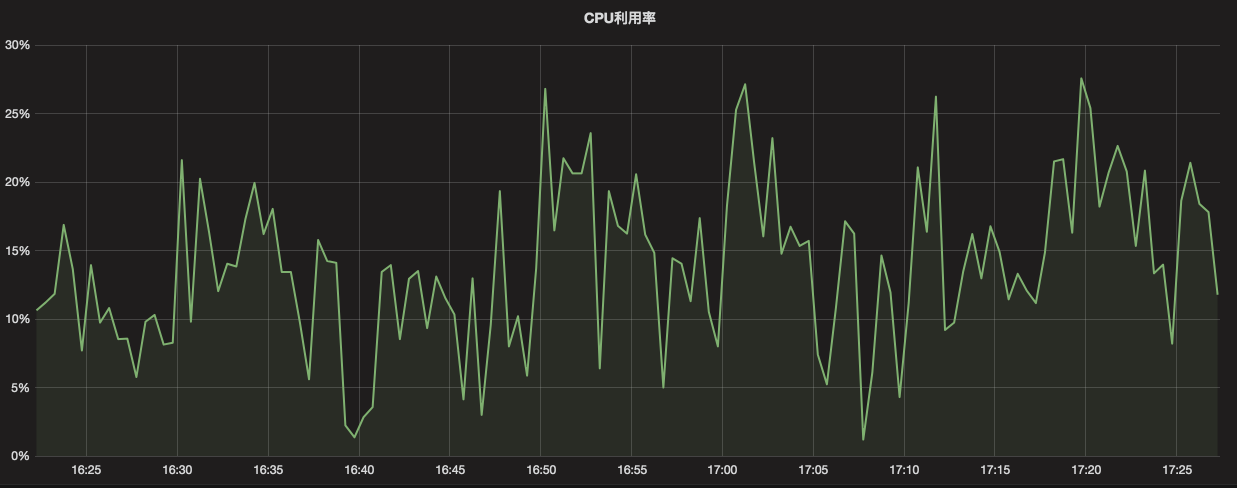
然而 CPU 抖动却非常频繁:
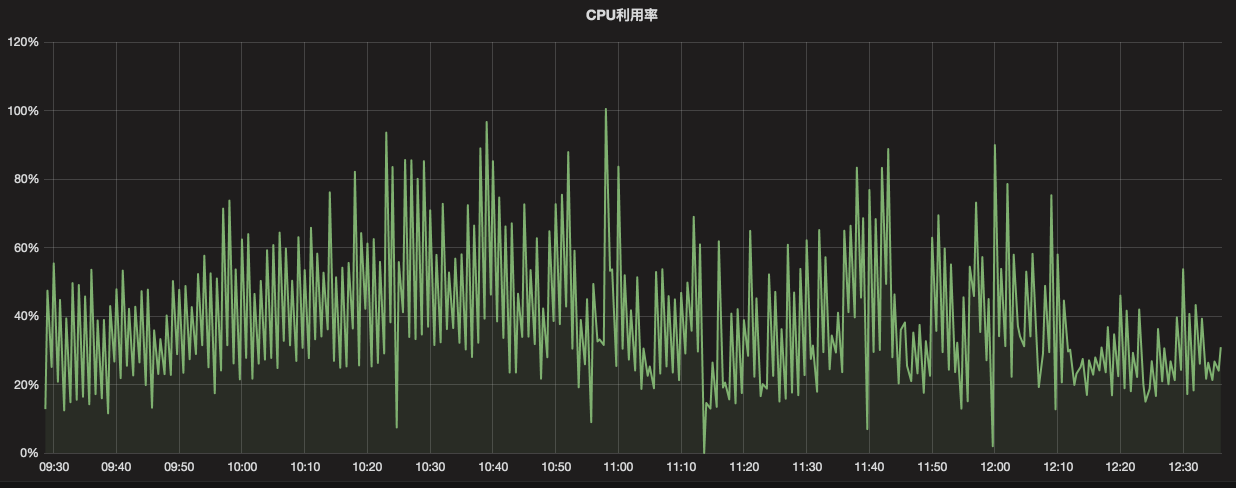
上图还没有完全说明问题,因为我们的监控系统是 30 秒收集一次,上图是个两分钟的平均值展示。如果从 top 指令看,则是时不时地飚高到 80% - 90% 甚至 100% 以上。
按照以往的经验来看,十分钟一两兆这样的数据量写入,不至于会长期占用这么高的 CPU。
perf top
执行 perf top 查看到如下情况:

看到 MySQL 的几个函数占用了较高的 CPU:
buf_get_n_pending_read_ios()
ut_time_ms()
buf_flush_page_cleaner_coordinator
srv_check_activity(unsigned long, unsigned long)
查看代码,可以看到 storage/innobase/buf/buf0flu.cc 里的 buf_flush_page_cleaner_coordinator 线程,刚好有这三个函数:
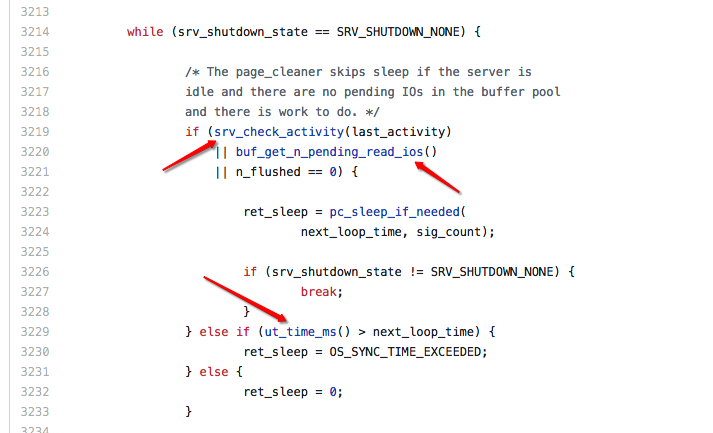
这个是 innodb buffer pool 后台刷新协调线程,看起来在这个 while 循环里,srv_check_activity 和 buf_get_n_pending_read_ios 这两个函数在 if 判断里面,一定是会被执行到的,既然后者占用的比例较高,所以先来看下后者究竟在做什么。
buf_get_n_pending_read_ios
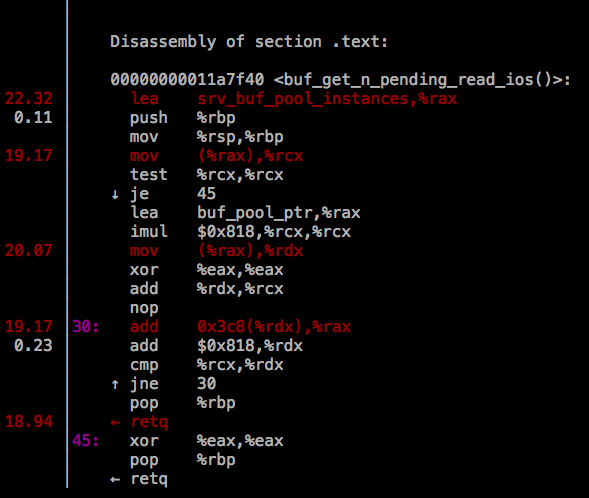
通过 perf top 的 Annotate 功能,可以查看到这个函数的 TEXT 段:
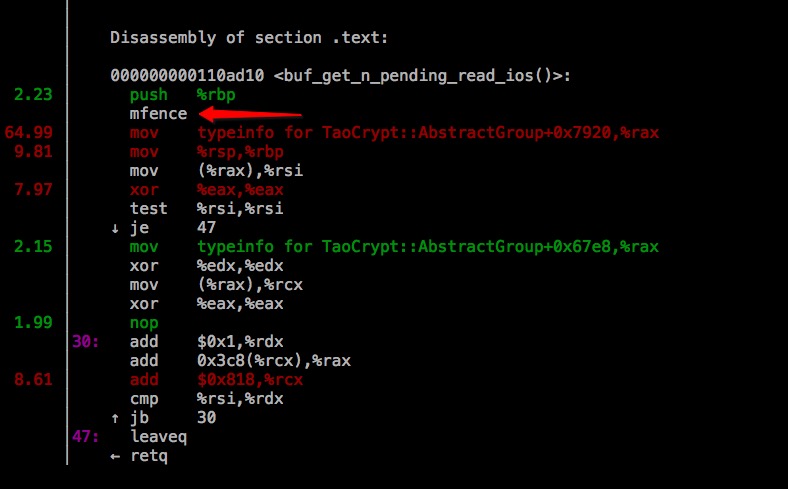
对应源码 storage/innobase/buf/buf0buf.cc 中的该函数:

对照上面的汇编,30: 那段比较明显是 for 循环;而
mov %rsp,%rbp
是将被调函数的栈帧栈底地址放入 bp 寄存器中,是准备开始调用函数了。明显地,在这个函数里,就只有 buf_pool_from_array(i) 这个函数了,那么我们需要查的占了 64% CPU 时间的这两行指令:
mfence
mov typeinfo for TaoCrypt:AbstractGroup+0x7920,%rax
看起来跟
os_rmb;
这行有比较大的关系。(以上是我不靠谱的推测 ...)
再来看下 os_rmb 这个宏是干什么的:

可以看到是编译的时候根据编译环境来定义的。
查看了 MySQL 启动日志,发现问题机器上是:
2017-11-15T10:49:50.445980+08:00 0 [Note] InnoDB: GCC builtin __sync_synchronize() is used for memory barrier
而刚好,在另外一台正常机器,我看到的是:
2017-03-02T18:32:47.595244+08:00 0 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier
看了下网上的资料,memory barrier 是内存屏障,编译器用来保证指令执行顺序的。__sync_synchronize 属于比较 legacy 一点的实现,而 __atomic_thread_fence 是比较新一点的实现。
至于为什么问题机器上用了 __sync_synchronize ,是因为同事之前因为某种原因自己编译了 Percona Server,而不是用 Percona 的二进制包,这是编译环境导致的问题!
我重新在我们的系统上编译了下,果然是看到了这些输出:
-- Performing Test HAVE_GCC_ATOMIC_BUILTINS
-- Performing Test HAVE_GCC_ATOMIC_BUILTINS - Failed
-- Performing Test HAVE_GCC_SYNC_BUILTINS
-- Performing Test HAVE_GCC_SYNC_BUILTINS - Success
__atomic_thread_fence 实现的 os_rmb 是这样的:
问题环境用官方包替换之后,我们看到 perf top 里,buf_get_n_pending_read_ios 已经在第一页看不到了:

从 MySQL 进程来看,buf_get_n_pending_read_ios 占用 CPU 的比例也下降了 (之前是 35% 左右) :

ut_time_ms
这是个获取时间的函数,先用 systemtap 确认下是否它的调用方 ( Percona 官方包支持 function 探测):
probe process("/usr/local/mysql/bin/mysqld").function("ut_time_ms@*").return {
printf ("%s <- %s\n", thread_indent(-1), probefunc())
}
probe timer.s(10) {
exit()
}
执行:
# stap -v mysql.stp > res.txt
# awk '/<-/{a[$NF]++}END{for(i in a)print i, a[i]}' res.txt
buf_flush_page_cleaner_coordinator 100952
buf_lru_manager 40
_Z15buf_page_createRK9page_id_tRK11page_size_tP5mtr_t 1
_ZL13pc_flush_slotv 28
可以看到这个函数基本上都是 buf_flush_page_cleaner_coordinator 调用的。
查看了后台刷新协调线程的代码,共有 8 处 ut_time_ms 函数调用。
谷歌了一下,有搜到 gettimeofday 的优化,都是提到了使用 VDSO,这是我们环境中默认开启的:
# cat /proc/sys/kernel/vsyscall64
1
确实用 strace -c 追踪后台刷新协调线程只能看到一些 IO 方面的系统调用:
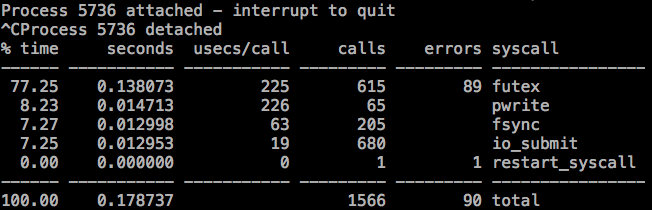
代码太长,没看懂,借下这篇文档中的分析:

如果单纯从减少 buf_flush_page_cleaner_coordinator 的 ut_time_ms 调用来说,让调度进程多去等待 buffer pool instance 处理,而不是一直在线程里不停执行 ut_time_ms,应该也算一种思路吧。(这又是我的不靠谱主观臆测 ...)
在 MySQL 5.7 中,如果不显式设置 innodb_buffer_pool_instances 这个参数,当innodb buffer size 大于 1G 的时候,就会默认会分成 8 个 instances,如果小于 1G,就只有 1 个 instance。
环境上的 MySQL,innodb buffer size 只设置了 256M,将其改大成 1G 之后,可以看到 buf_flush_page_cleaner_coordinator 调用 ut_time_ms 的次数确实减少了:
buf_flush_page_cleaner_coordinator 41140
buf_lru_manager 80
_ZL13pc_flush_slotv 40
这其实是个玄学,因为不知道是不是改大了 innode buffer size 带来的。不过呢,测试过单纯改大 innode buffer size 并不能改善 MySQL CPU 抖动的情况。
暂时的结果
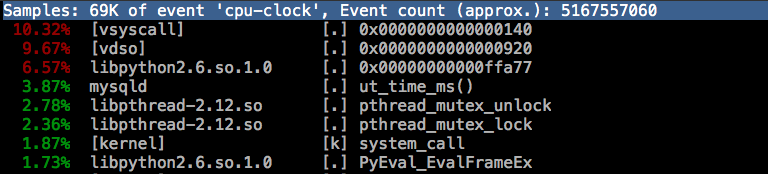
同样的读写负载下,可以看到比优化之前的均值 60% 好了很多,但其实从 top 看到有时候还是会飚高到 50% - 70% 左右,但频率比优化前低了很多。
perf top 的结果:
或许之后可以测试下 5.7.17 之后的版本:
https://bugs.mysql.com/bug.php?id=87637
参考资料
https://github.com/percona/percona-server/blob/f9157b81b9d86b3dacb72267deeeee3660895f75/storage/innobase/buf/buf0flu.cc
http://www.yunweipai.com/archives/17404.html
https://as.h5con.cn/articles/41146
http://blog.csdn.net/lubing20044793/article/details/38897729
http://www.trueeyu.com/2015/03/18/gettimeofday/
https://bugs.mysql.com/bug.php?id=87637
最后
有官方包用官方包,没事不要自己编译软件包玩!!